

 home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search

John A. Gerlt¹, Patricia C. Babbitt², Conrad C. Huang³, and Thomas E. Ferrin³
¹
Department of Chemistry
and
Biochemistry
University of Illinois, Urbana
²
Department of Bioengineering and Therapeutic Sciences
University of California, San Francisco
³
Department of Pharmaceutical Chemistryy
University of California, San Francisco
This project seeks to lay the theoretical basis for understanding how enzyme structures evolve to provide enzyme chemistry through the study of enzyme families, superfamilies, and suprefamilies. Understanding the interdependence of structure and function in enzymes requires insight into the hidden constraints that nature has engineered into a given structural template. As the genome projects move beyond the data accumulation phase, it now becomes possible to investigate this issue by asking how often and for what range of functions nature has used a common structural scaffold. Our primary focus is the comparative analysis of distantly related proteins at the tertiary structural level. The value of this approach is its ability to illuminate hidden relationships in the structure-function paradigm that cannot be observed by studying one protein at a time. Our goal is to provide a rational basis for protein engineering founded on the unique structure-function characteristics of a given superfamily. We are using molecular modeling tools to determine the variable and conserved elements of the members of a superfamily from comparisons and superposition of structures. From these data, we are developing a structural template for the superfamily that will allow us to differentiate the structural elements that mediate common function from those that give rise to specificity. Molecular docking methods are used to refine our understanding of the chemically relevant site common to a given superfamily and used to predict alternative substrates or inhibitors for superfamily members. Thus, we can evaluate the feasibility of engineering protein structures for specific new functions prior to a large-scale investment of experimental effort.
As an example, the TIM barrel class of enzymes provides one suprafamily for developing our methodology. Named for the prototypical model, triosephosphate isomerase, these structures mediate a wide range of chemical reactions critical to biological survival and have been estimated to comprise as much as 10% of soluble enzymes.
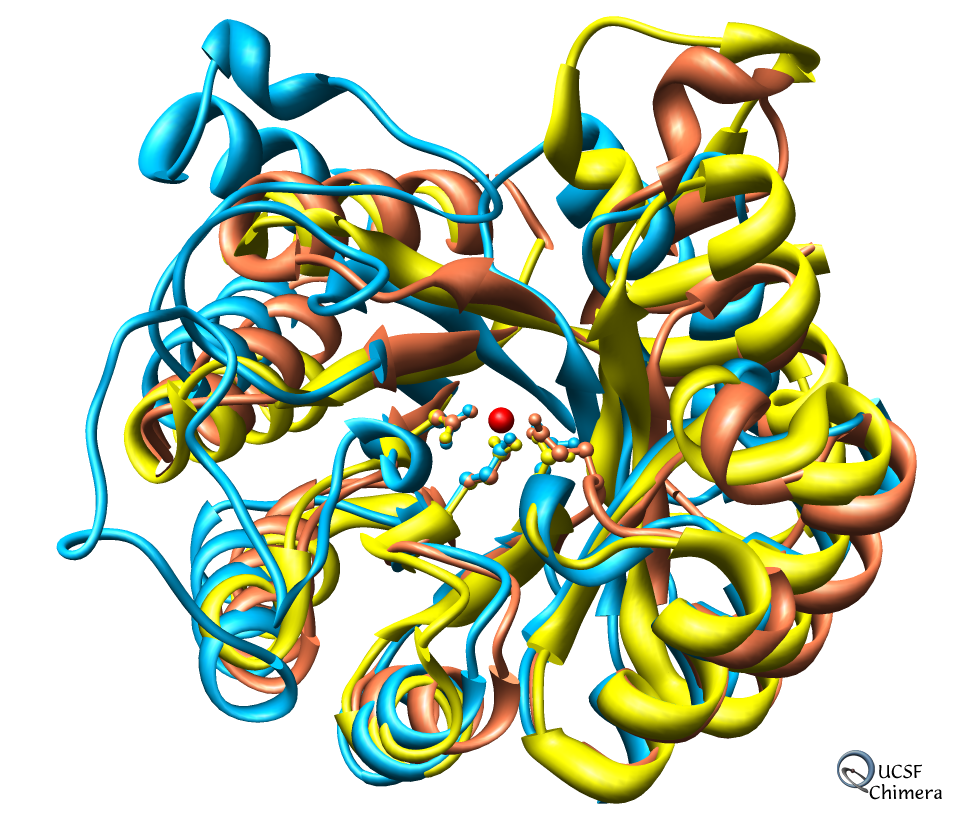
For the catalytic domains, the TIM barrel fold is perhaps the best understood class of protein structures. One superfamily within this group is the enolase superfamily, perhaps the best described example of a superfamily encompassing a wide range of chemical reactions, substrates, and biochemical functions (see image at right or download this high resolution png image). It includes open reading frames of as yet undetermined function, proteins that have not been well-characterized mechanistically, and proteins that have been extensively characterized both structurally and biochemically. As such, the enolase superfamily provides a good test set for our purposes: the well-characterized members will serve as controls for evaluation of our predictive tools while the less well-characterized members will serve as good test cases for development of our investigative tools.
For additional details about this research work, see:
- P.C. Babbitt et al., "The enolase superfamily: A general strategy for enzyme-catalyzed abstraction of the alpha-protons of carboxylic acids," Biochemistry, 35:16489-16501 (1996).
Acknowledgments: This research is supported by the National Institutes of Health, grant GM60595 (P.C. Babbitt, P.I.), and the National Center for Research Resources, grant P41-RR01081 (T.E. Ferrin, P.I.). Molecular models were created using the suite of programs available in UCSF Chimera.
Laboratory Overview | Research | Outreach & Training | Available Resources | Visitors Center | Search
{kind=link}